 Interactive t-SNE
Interactive t-SNE
 Video Perspectives
Video Perspectives
 Industrial Haptics
Industrial Haptics
 Better t-SNE
Better t-SNE
 Beyond t-SNE
Beyond t-SNE
 The Drone Perspective
The Drone Perspective
 Incessant Visuals
Incessant Visuals
 Material Illusion
Material Illusion
ML Interface: DNN Models Can Expose Training Live, Allowing an Operator to Guide and Improve Training
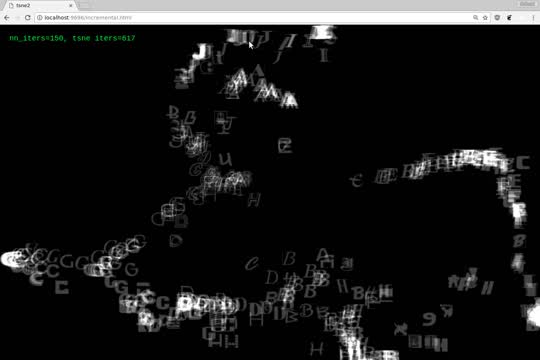
I demonstrated a sketch from a few months ago that shows progress in training a neural network model in realtime, and on the basis of that visualization, allows interactive feedback from the user to guide the training process.
To have an intuition about the development of a model, t-SNE embeddings of validation set are shown, with features extracted from the network’s penultimate layer.
The screen flashes red every few seconds to indicate that features from an updated model are available. Small modifications to Andrej Karpathy’s tsne.js implementation allow for the embedding to be updated incrementally; characters animate to their new positions.
Clicking on any data point adjusts the position of all other points to absolute euclidean distance to the selection. By maintaining the angle from the t-SNE embedding and only altering magnitude of the vector, structure is preserved from t-SNE; generally, points that are nearby in the t-SNE space remain fixed, while distant points become more distant.
Finally, by control-clicking on a point and dragging the mouse, a hypersphere can be defined relative to the selected data point. The centroid and radius are sent to the TensorFlow script (through extensions DanyQ added to his excellent vizterm), which then restricts backpropagation to input data within bounds. So if you noticed for example that C’s and G’s were in a similar feature-space, you could focus training on developing features to distinguish those particular data points.
Video Interface: Assuming Multiple Perspectives on a Video Exposes Hidden Structure
A few days ago I re-created one of my earliest video interfaces, from 2011, which had been languishing in a state of bit-rot. It allows for the interactive design of video timelines.
The default view is to show one frame of video every five seconds, 12-per-line, such that a minute of video is represented on each line.
Two dimensions of control are offered. The frames can be cropped, for example so half a frame of video is shown every two-and-a-half seconds, 24-per-line. And when a video is cropped, you can pan left and right within each frame.
The big reveal of this interface comes when the frames are cropped down to a single column of pixels per line, 25-per-second. All of a sudden, smooth and recognizable form emerges from the chopped up digital landscape.
Haptic Interface: Software Expression and Illusion Is Even Possible in the Physical World
Finally, I showed recordings from early-stage development of an industrial-grade haptics device made in collaboration with DanyQ last Winter.
The basic mechanism connects force sensing (initially from disassembled luggage scales) with proportional actuation of a stepper motor. By connecting sensing and actuation, the computer can create the illusion that you are moving an object back and forth in physical space (while in fact all of the motion is mediated by the computer).
Our second iteration included two degrees of haptic control.
In addition to directly mapping the detected forces to actuation, the computer can also mediate the interaction. Here a virtual “wall” is applied before the edge of the threading, preventing the operator from disengaging the carriage from the board.
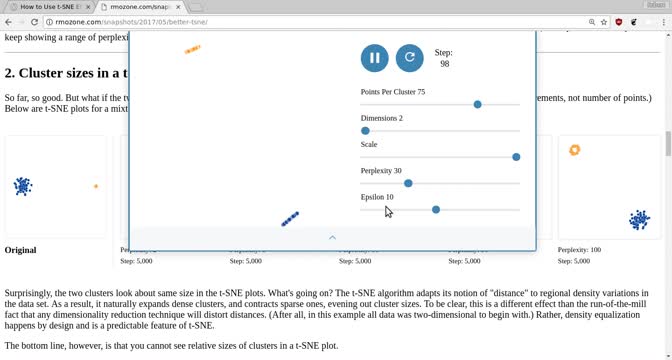
Fixing t-SNE with One Simple Interaction
In order to make the hypersphere selection in the interactive training study, I developed a method to “de-project” from t-SNE relative to any point. In addition to allowing an accurate range selection, this technique addresses many of the known failure modes of this (and any other) embedding.
Last year, Wattenberg, et al. published an article articulating several hazards of reliance on t-SNE; by patching their visualizations with my interaction method, an operator can trivially avoid mis-reading the embedding.
t-SNE gives us the illusion that we can comprehend high-dimensional space, but its illusion confuses the mathematical with perceptual. By adding a perceptual "ground truth" (at least to the distance measure t-SNE purports to optimize), it becomes a far more powerful tool.
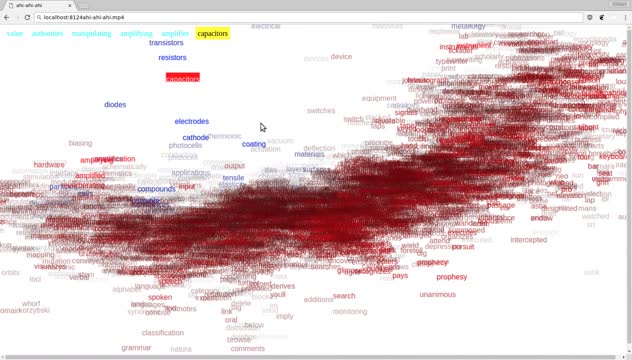
Beyond t-SNE: a Glimpse of 300 Dimensions
Curious how an interaction within feature-space would translate to the high-dimensional vectors typical of deep learning, I returned to an old sketch on augmenting Doug Engelbart’s report on augmenting human intellect.
The sketch initially created a bi-directional mapping between the report and an embedding of all of its words.
Coming back to this, I updated the vectors with the 300-dimensional pre-trained embeddings from Facebook’s fastText. As before, t-SNE creates an ostensibly plausible map: a quick glance shows semantic clustering. However, de-projecting viscerally shows the dizzying quantity of information lost by t-SNE: very little local structure from the euclidean distance matrix is preserved in t-SNE.
Interaction should elucidate, and not simply in/validate. By utilizing animation, relationships between t-SNE and euclidean distance can be thickly expressed. Moreover, the relationship between successive words can be probed. I reify the speed and direction of word motion with a red/blue shift. At the suggestion of James Bradbury, I added breadcrumbs allowing a visible path; arrow keys can be used to toggle back and forth through the chain.
Someone in the audience asked me about hyperbolic embeddings, which I have not explored. However, this study suggests to me that an interaction can lead to usage of less sophisticated embeddings, rather than more: in a high-dimensional space, the interaction is more evocative and expressive than a static image or fixed 3d space will ever be (ie. or else all of those dimensions are for naught). To use the language of developmental psychology, this interaction is a transitional object that may help wean us off of our inherently-distorted low-dimensional diagrams. This technique would work just as well with a PCA base, or with some slight modifications that maintained de-projected positions, could even define an embedding from random initialization.
The Drone Perspective and the Meaning of Context
Working with language and images highlights both the strengths of deep learning—achieving results far surpassing procedural scripting—and also the limitations of a rigid conception of “correctness.” Innumerable turns of language along with analogical thinking (for example consider how the compliment “that’s sick” takes a health metaphor and then inverts its sentiment), defy closed-form and literal interpretations. Likewise images can capture and reflect facts from physical reality, just as they can evoke through tone and composition and reference. Classification tasks are rather like a pretense that allows for the derivation and modeling of sophisticated features. These features seem to capture nuanced, layered, and even contradictory meaning.
Though I suspected that the crowd at Google already understood how word embeddings are derived, I explained that they are generally trained on large text corpora and model a word by its context. Words that show up around similar words should have similar feature vectors; context as definition.
With that in mind, I showed a video piece that I made at the end of 2015, called A Little More Stable. It was the final development in four odd years of exploration of video representation, and is a highly complex and conflicted piece.
Technically, it is an attempt to present an entire video at once. The viewer is invited to watch from any moment, or to let the larger structure wash over them. Likewise the sound aspires to transcend linear time. While you can “focus” your ears on the linear video stream (between the red lines), you can also listen chronologically, or else look anywhere on the video timelines and try to hear from that moment (using the textual cues).
Beyond the technical construction, the piece has a self-critical dimension. The subject matter concerns drone imaging, and I was becoming concerned that my video timelines were distancing viewers, perhaps with the same hazards as come with aerial vantage over a territory.
The source material is an advertisement made by a technology startup that was “pivoting” from military to consumer applications. If word embeddings posit meaning through context, what does a technology carry with it as it moves from military to consumer applications?
The rendering was made using the Gentle tool I developed, and I have an alternative representation of the advertisement that superimposes a clickable transcript over the video. In this way, you can focus on a close read of language—in a video.
At the first scene of the playground, the father speaks of “high danger,” as if the kid is still in a war zone.
The investor talks about the importance of memory to a consumer: it enables “torture” of the child, a putative person of interest.
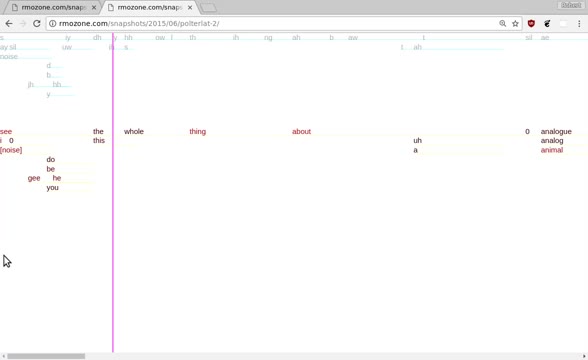
Incessant Synesthetic Visualization as a Development Artifact
While I was developing Gentle, I made an interactive visualization of the lattice datastructure used by Kaldi.
You can see some of the alternative pathways through the decoding graph, and this study made clear how large a role speaker adaptation plays in the accuracy of the model.
When we start decoding at the second speaker, it’s clear at first until we hit another “wall” in the lattice: an out of vocabulary word.
I have come to value incessant visual communication in any system that I design. One of the design goals of the haptic device was to program all of the control logic in a high-level programming language (not on-board the microcontroller).
Here you can see the “debugging” screen projected over the device.
Illusions are in a Constant (Productive) Tension with Reality
My video research brought me to a tension between showing the illusion of motion and the static bucket of frames that enables it. Both are useful, and while they are bound to one another, there isn't usually a way to have both. The illusion is useful because it matches our perceptual system, while at the same time the point is a transmission of some reality.
There’s a deep tension in a computing system that deals with media between the textual/numeric representations native to computing, and the illusionary forms that media takes.
The cells of the spreadsheet become a jail for the media it represents.
An interactive timeline allows moving between the qualitative and quantitative: playing the frames as a flip-book, and collapsing them into graphs.
After all of my developments in virtual representations of video, a one-off experiment putting together a three-ring binder convinced me of the importance of considering the physical. With even the most minimal computer vision system (that would simply recognize the page and play the video it represented), I achieved a (literal) tactility “flipping through” video that no virtual interface could ever provide.
Attempts to extend this study into more sophisticated interactions in the physical world led me directly to modern deep learning.
Dataset Interface: Underexplored Territory
In response to questions, I discussed the novelty of access to large, well-curated public datasets. I’ve started prototyping interactions that allow human navigation of such datasets.
Could an interface allow you to translate into a language you don’t speak on the basis of WMT data?
Do the ideas of word2vec make sense with film subtitles? What do the visuals and tone/cadence add to the text?
Throughout the day at Google, I met many amazing people working on all manner of machine learning, and the requisite tooling. A big thanks to Cassandra Xia for hosting me, and to everyone (Eric, Sara, Katherine, David, and Dandelion) who took time out of their schedules to meet with me.